2025. 4. 15. 17:48ㆍKubernetes
"A workload controller is a container platform entity that watches the state of your pods and then requests changes where needed."
https://www.ibm.com/docs/en/tarm/8.15.0?topic=platform-workload-controller
Workload controller
A workload controller is a container platform entity that watches the state of your pods and then requests changes where needed. Examples of workload controllers are Deployments and StatefulSets. A single workload controller can contain one or more contain
www.ibm.com
1.Deployment
Kubernetes에서 Stateless 상태로 Application을 배포하고 업데이트하고 관리하기 위한 가장 기본적인 Workload Resource 이다.
내가 원하는 Pod의 개수, 이미지 버전, 설정 등을 정의하면 그 상태를 자동으로 유지시켜주는 컨트롤러이다.
Deployment의 기능은 여러 가지가 있다.
Deployment 구성요소
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-container
image: myimage:1.0
ports:
- containerPort: 80
여기서 replicas 는 유지할 Pod 의 개수
selector 는 어떤 pod들을 관리할지를 정의 (label selector)
template 실제로 생성될 Pod의 정의 (metadata + spec)
strategy 업데이트 전략 (기본적으로는 RollingUpdate 를 사용한다.)
- Pod 개수 유지 (Self Healing)
사용자가 지정한 복제본 수만큼 Pod 의 수가 유지되도록 보장하며, Pod가 죽으면 자동을 재생성된다.
1.1 Rolling Update
이름그대로 배포 시 업데이트 방식이다.
아래와 같은 업데이트 흐름을 가진다.
1) 새로운 이미지(tag 변경)로 Deployment 수정
2) kube-controller-manager가 변경 감지
3) 새 ReplicaSet 생성 → 기존 ReplicaSet의 Pod 점진적 제거
4) Pod 교체가 완료되면 새 상태로 고정
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1 # 새 Pod을 최대 몇 개 더 만들 수 있는지
maxUnavailable: 1 # 동시에 몇 개까지 비활성 상태일 수 있는지
이때 위와 같이 RollingUpdate 방식을 설정할 수 있다.
1.2 Rollback
Deployment는 Revision을 관리하기 때문에 Rollback 이 쉽게 가능하다
kubectl rollout undo deployment my-app # 이전 버전으로 롤백
kubectl rollout history deployment my-app # 특정 버전으로 롤백
- Deployment 내부적 동작 원리
[Deployment]
↓
[ReplicaSet] ← 새 버전이 생길 때마다 새 ReplicaSet 생성됨
↓
[Pod] ← ReplicaSet이 관리
위와 같이 Deployment는 ReplicaSet을 생성, 삭제 및 업데이트하는 역할만한다.
실제로 Pod를 직접 제어하는 건 ReplicaSet 이며 업데이트 새로운 ReplicaSet을 생성하여 대체하는 것이다.
이러한 특성을 가진 Deployment 는 언제 사용해야 할까?
웹 서버, API 서버 등 무상태 앱, CI/CD pipline 에서 배포 자동화 대상 그리고 빈번한 업데이트가 필요한 서비스에 적합할 것이다.
반대로 부적합한 경우는 Stateful 이 필요한 경우인 DB, Kafka, Redis 등은 StatefulSet 을 사용하고
Log 수집 이나 모니터링 이벤트는 DaemonSet을 사용할 것이다.
2. ReplicaSet
ReplicaSet은 특정 Label Selector를 만족하는 pod를 지정된 개수만큼 self healing 해주는 Controller 이다. Pod의 개수를 관리해주는 핵심 Resource 이지만 내부적으로는 Deployment가 ReplicaSet을 생성 및 관리하기 때문에 단독으로 사용되는 경우는 거의 없다.
2.1 지정된 수의 Pod 개수 유지 (Self Healing)
목표한 pod 수를 설정하면 replicas 개수만큼 pod 수를 생성하고 많으면 제거한다.
2.2 Label Selector 기반 Pod 관리
Replicas 는 selector filed 에 정의된 Label Selector 기준에 따라 어떤 Pod를 자신의 관리 대상(Pod)로 삼을지를 결정한다.
matchLabels (정확히 매칭되는 Key - Value Pair)
matchExpressions ( in, notion, exist 같은 조건을 사용하는 방식)
등 다양한 Label Selector 를 지원한다
2.3 ReplicationController 의 발전형
ReplicaSet은 RC를 대체하기 위해 만들어졌다. RC는 equals 매칭만 가능했지만 RS 는 set based selector를 제공하여 좀 더 유연한 Label Selector 구성이 가능해졌다.
2.4 단독 사용 시 Update 및 Rollback 수작업
ReplicaSet을 단독으로 사용할 경우 Rolling Update 와 같은 기능을 직접 구현하거나 스크립트를 작성해서 수작업으로 처리해야한다.
ReplicaSet 을 위해서 사용되는 대표적인 설정은 예를 들면 다음과 같다.
- replicas: 3: Pod 3개를 유지하고 싶다는 설정
- selector: matchLabels: 어떤 라벨을 가진 Pod을 추적할지 명시
- template 내부: 어떤 Pod을 생성할지 구체적으로 정의
template:
metadata:
labels:
app: my-app
이 경우 지정된 app:my-app 을 label 로 갖는 Pod 이 3개 생성된다.
3. StatefulSet
stateful apps 를 위한 Kubernetes의 Controller 이다.
DB, 메세지 브러커처럼 Cluster 내의 각 instance(pod)가 고유한 상태나 identity를 가져야할 때 사용한다.
StatefulSet은 Pod의 Name, Network, Storage 를 보장해준다.

3.1 Stable Pod Identity
StatefulSet으로 생성된 Pod은 my-statefulset-0, my-statefulset-1, … 와 같이 일련번호(ordinal)가 붙은 이름d을 갖는다.
각 pod 의 이름은 유일하며 Application Level 에서 Pod를 구분해야하는 경우에 유용하다.
3.2 Stable Network identity
StatefulSet을 만들 때 ServiceName 이라는 항목을 지정해준다. 이때는 보통 Headless Service (ClusterIP 가 없는 서비스)를 이용한다
- Headless Service 는 ClusterIP가 없는 형태의 Service 이다.
ClusterIP : None 으로 설정하면 Kubernetes 가 해당 Service 에 대해 별도의 ClusterIP를 부여하지 않는다. 대신 DNS 해석 시 개별 Pod들의 IP를 직접 반환한다. 이를 통해 Pod 각각을 DNS로 바로 접근할 수 있게 할 수 있다
StatefulSet과 Headless Service가 함께 사용되는 이유는
Pod 마다 고유의 DNS가 필요하기 때문에
일반적인 Service는 하나의 IP 혹은 DNS Name 에 여러 개의 Pod 를 묶는다. 이때 어떤 pod 가 매핑될지는 로드밸런서가 동적으로 정한다. 이 경우 Pod를 개별적으로 식별할 수 없기 때문에 Headless Service 를 통해 DNS 요청 시 각 Pod IP 에 직접적으로 접근할 수 있게 구성하는 것이다.
spec:
serviceName: "mysql-headless"
replicas: 3
...
Pod는 podName.serviceName.namespace.svc.cluster.local 같은 DNS Host name을 가진다.
ex) db-0.db-headless-service.default.svc.cluster.local
이를 통해 Pod 를 재시작하거나 다른 Node 로 이동해도 DNS 주소가 변하지 않고 동일하게 유지된다.
3,3 Ordered, Graceful Deployment & Scaling
StatefulSet 은 Pod 를 0번부터 차례대로 생성한다.
(0번이 Ready 상태가 된 후에야 1번을 생성, 1번이 Ready 후에야 2번을 생성…) 하는 방식이다.
종료나 스케일 다운 시에는 역순으로 차례대로 내려간다
이러한 순차적인 오케스트레이션은 데이터 동기화, Leader - Fllower 전환 등 상태가 중요한 애플리케이션에 필수적이다.
3.4 Persistent VolumeClaim 자동 매핑
StatefulSet에 정의된 volumeClaimTemplates는 Pod 개수만큼 각기 다른 PVC(PersistentVolumeClaim)을 생성한다
예: mysql-data라는 볼륨이 있으면, 실제로는 mysql-data-mysql-0, mysql-data-mysql-1 등 Pod별 PVC가 자동으로 만든다.
Pod 가 재시작되어도 자신에게 할당된 PVC(Storage)를 그대로 사용하기 때문에 기존 데이터가 유지된다.
* 운영 시 주의점
- Headless Service는 Pod 마다 고유 DNS 를 만들기 위해 사용하였다 하지만 외부에서 접속을 해야한다면 별도의 일반 Service 추가로 구성해야한다.
- StatefulSet은 순차적으로 Pod를 증가 및 감소 시키기 때문에 스케일 조정에 시간이 걸린다. 그래서 데이터 동기화나 샤딩 구조가 있을 때 작업이 잘 진행되는 지에 대해 모니터링이 필요하다
- StatefulSet도 RollingUpdate 전략을 지원한다. 원하는 경우 partition 설정 등을 통해 점진적 업데이트가 가능하다. 하자민 무중단으로 업데이트가 어려울 수 있으니 Leader Node 전환 및 장애 감지 등에 신중해야한다.
- Persistent Volume
Pod 이 장애로 재시작되거나 node 가 변경되더라도 동일 Volume으로 remount 할 수 있다. 하지만 실제 물리적인 스토리지(EBS,NFS, Ceph 등)의 구성과 연결 설정을 고려해야하며 RWX(다중 노드에서 동시에 읽기 / 쓰기) 모드가 필요한 경우가 아니면 대체로 ReadWriteOnce Mode 를 사용한다.
- 기본적으로 Pod를 삭제해도 PVC까지 자동으로 삭제되지 않는다. 필요한 경우 VolumeReclaimPolicy나 RetentionPolicy 등으로 PVC 자동 정리를 설정할 수도 있다.
4. DaemonSet
Kubernetes에서 Cluster 내 모든 Node 에 Pod을 배포할 때 사용하는 Controller 이다.
주로 로그 수집(Fluentd/Logstash)이나 모니터링 에이전트(Prometheus Node Exporter), 보안 에이전트(Falco)처럼 각 노드마다 하나씩 에이전트를 실행해야 하는 상황에서 활용된다.
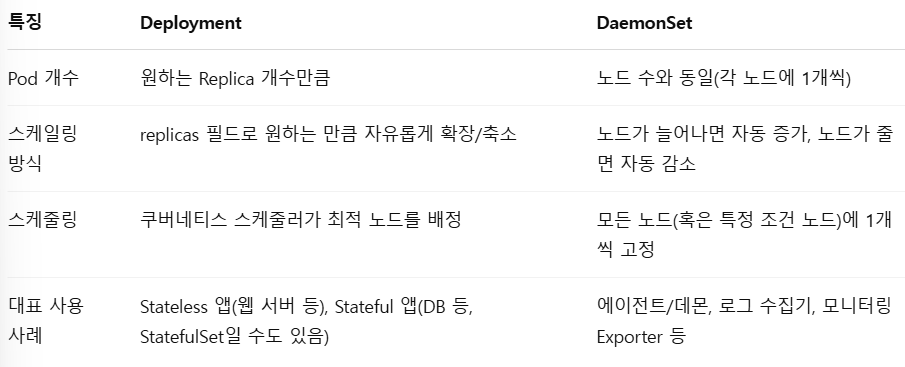
DaemonSet은 Node가 n개이면 pod도 n 개를 생성한다. 새로운 node 가 Cluster에 추가되면 DaemonSet은 자동으로 해당 Node에도 pod를 추가로 배포한다. Node 가 제거되면 해당 node 에서 동작하던 pod 도 자동으로 사라진다.
Deployment 나 ReplicaSet은 Scheduler 가 Pod를 어느 노드에 배치할 지 결정하지만 DaemonSet 은 모든 노드를 대상으로 하기 때문에 스케줄링 Logic 이 다르다. 모든 Node(혹은 특정 조건 Node)에 1개씩 고정적으로 스케줄링 되어있다.
+ 추가설정
- Node Selector / Affinity
spec.template.spec.nodeSelector나 affinity 설정을 통해, 특정 라벨이 붙은 노드에서만 DaemonSet Pod이 동작하도록 제한할 수 있다. 예를들어 Worker Node 에만 배포하거나 GPU Node 에만 배포하는 방식
- Tolerations
노드가 taint를 가지고 있는 경우, DaemonSet이 그 노드에 스케줄링되려면 해당 taint에 대한 toleration이 필요하다.
예: NoSchedule taint가 있는 노드라도 반드시 DaemonSet을 돌려야 하는 경우, tolerations 설정을 통해 Pod을 실행할 수 있다.
- Update Strategy
DaemonSet도 업데이트 전략(RollingUpdate, OnDelete)을 가질 수 있다. RollingUpdate로 설정하면, 노드별로 차례대로 Pod이 재생성된다. OnDelete라면, 관리자가 수동으로 Pod을 삭제할 때만 새로운 버전의 Pod이 생성다.
- Host Networking / Privileged Mode
로그 수집기, 보안 에이전트, 모니터링 에이전트 등은 노드의 호스트 네트워크나 파일시스템 접근이 필요할 수 있다. 이 경우 hostNetwork: true, hostPID: true, privileged: true(혹은 SecurityContext)을 설정하는 식으로 컨테이너에 특수 권한을 부여할 수 있다. 단, 보안적으로 주의해야 한다
5. Job
Kubernetes에서 One Time Task 를 실행하기 위한 Controller 이다.
웹 서버나 DB 같은 지속적으로 동작하는 애플리케이션이 아니라 특정 스크립트나 프로그램을 한 번 실행하고 종료해야하는 배치 및 백그라운드 작업에 주로 사용된다.
Job 은 Pod를 생성하고 작업을 완료하고 종료하는 목적을 가진다. Pod 이 성공적으로 완료되면 Job 도 완료 상태가 된다.
작업 도중 Pod 이 오류로 실패하면 설정에 따라 재시도(backoff) 할 수 있다. 이때 backoffLimit (재시도 횟수)와 restartPolicy (실패 시 Pod을 재시작할 지 여부) 를 통해 재시도 전략을 조정할 수 있다.
Job이 생성되면 Kubernetes Scheduler 는 해당 Job을 위해 Pod을 1개 이상 생성한다. Pod 이 성공적으로 종료되면 Job Success 상태가 되고 Pod는Completed 상태로 유지되거나 Kubernetes 설정에 따라 Garbage Collection 대상이 될 수도 있다.
apiVersion: batch/v1
kind: Job
metadata:
name: db-migration
spec:
template:
spec:
containers:
- name: migrate
image: myapp:migrate
command: ["./migrate.sh"]
restartPolicy: Never
backoffLimit: 3
spec.template.spec.containers
여기서 restartPolicy: Never 은 Pod 가 실패하면 재시작하지 않고 Pod 를 새로 생성해서 재시도하게 한다. OnFailure 로 설정할 수 도 있다.
backoffLimit: 3
최대 3회까지 실패해도 새 Pod를 생성해서 재시도 한다. 3회 이상 모두 실패하게되면 Job 은 최종적으로 Failed 상태로 종료된다.
5.1 CronJob
특정 스케줄 (Cron 표현식) 에 따라 Job 을 주기적으로 생성하는 Resource 이다.
Job이 번만 실행되는 작업에 사용된다면 매일 3시에 실행해야하는 작업과 같이 주기적으로 Job을 주기적을 사용할 수 있게 하는 Resource 이다.
kind: CronJob
metadata:
name: db-backup
spec:
schedule: "0 2 * * *" # 매일 새벽 2시에 실행
완료되면 자동으로 정리되거나 History를 유지할 수도 있다.
6. Custom Controller (Operator)
Kubernetes는 기본 Controller 외에 사용자가 정의한 Resource를 자동으로 관리하고 싶을 때 사용한다.
Custom Resource Definition (CRD)와 함게 사용된다. 애플리케이션의 전체 수명 주기 관리가 가능하다
예를 들어 DB 설치 -> 백업 -> 모니터렁 -> 업그레이드 등을 자동화 할 수 있다.
ex)
Cert-Manager: TLS 인증서 자동 갱신
Prometheus Operator: Prometheus 및 Alertmanager의 수명주기 관리
ArgoCD Operator: GitOps 방식의 앱 배포
구성요소
CRD: 새로운 리소스 타입 정의 (예: MySQLCluster)
Controller (Operator): 해당 리소스를 감시하고 원하는 상태로 자동 조정
'Kubernetes' 카테고리의 다른 글
| Kubernetes Storage (0) | 2025.04.16 |
|---|---|
| Kubernets Ingress & Load Balancing (0) | 2025.04.16 |
| CNI(Container Network Interface) & Cluster Networking (0) | 2025.04.15 |
| Container Runtime & CRI (Container Runtime Interface) (0) | 2025.04.15 |
| kubelet / kubectl / kube-proxy / kubeadm (0) | 2025.04.15 |